




 [tta_listen_btn]
[tta_listen_btn]
 September 4 2025
September 4 2025


Ever feel like your database is running slower than it should? That’s where database optimization comes in; it involves making databases faster and more reliable. At the enterprise level, this becomes even more critical. Every second, companies execute millions of database queries, and the gap between an optimized and unoptimized system can determine success and failure.
Take Uber, for example, its ability to handle millions of rides daily depends entirely on robust database scalability and optimization techniques. So, whether you are dealing with slow query performance or scalability bottlenecks, let us tell you that database optimization is your key, and below are seven strategies that can help you.
So, let’s start with the basic intro to data optimization.
What is Database Optimization?
Database optimization is the process of improving the efficiency and performance of a database system. It can be done by applying techniques such as:
- Query optimization
- Indexing
- Schema design
- Caching
- Resource management
The purpose of optimization is to help the database handle workloads smoothly, deliver faster results, and use the storage or hardware resources effectively. This ensures a smooth flow of data through the system without bottlenecks, increasing the efficiency of operations.
Moreover, the subset of database optimization is database performance optimization, which focuses on increasing the speed and responsiveness. Ensuring queries run faster and workloads are executed effortlessly.
Let us tell you more reasons why data optimization is important.
Why is Database Optimization Important?
The optimization of the database helps in reducing the resource usage and costs, eventually increasing the system efficiency. Making it a necessity, not a luxury, for organizations around the globe by helping them reduce load time and improve query speed. Below are the top benefits of optimization:
Enhanced Application Performance
An application using an optimized database delivers a quicker response time, which is crucial during peak traffic hours. Therefore, optimization simply helps your system manage high demand effectively because a delay in the results can effectively cause the traffic to bounce back.

The database optimization techniques ensure that a database is ready to tackle these pressures efficiently and in a cost-effective manner.
Cost Efficiency
Companies improve query performance and storage management through database optimization. This helps reduce the need for computing resources and the need for extra hardware. Plus, it also helps in reducing maintenance costs and operational overhead while allowing faster and more efficient decision-making, which helps reduce errors and inefficiencies.
Scalability
An unoptimized database can cause the systems to become slow, inefficient, and resource-heavy. By streamlining queries, indexing data efficiently, and minimizing resource bottlenecks, an optimized database can manage increasing amounts of data. This also ensures that the system grows smoothly as demand rises, avoiding costly slowdowns and upgrades.
Data Security
An optimized database is not only efficient but also maintains the accuracy and security of data. In sectors such as healthcare, where precision is critical, database tuning and observability help in securing data while ensuring the efficiency of systems.
All in all, optimization is an effective method for improving the database performance in addition to improving its scalability and efficiency. If you are looking to make your database more efficient. Then let us share some data optimization techniques and strategies with you.
7 Strategies for Effective Database Optimization
It is not a short-term fix; rather, it’s a structured and comprehensive approach that helps in making databases more efficient in handling large amounts of data, complex queries, and varying workloads. At the same time, it maintains the performance speed and data precision.
a precision.
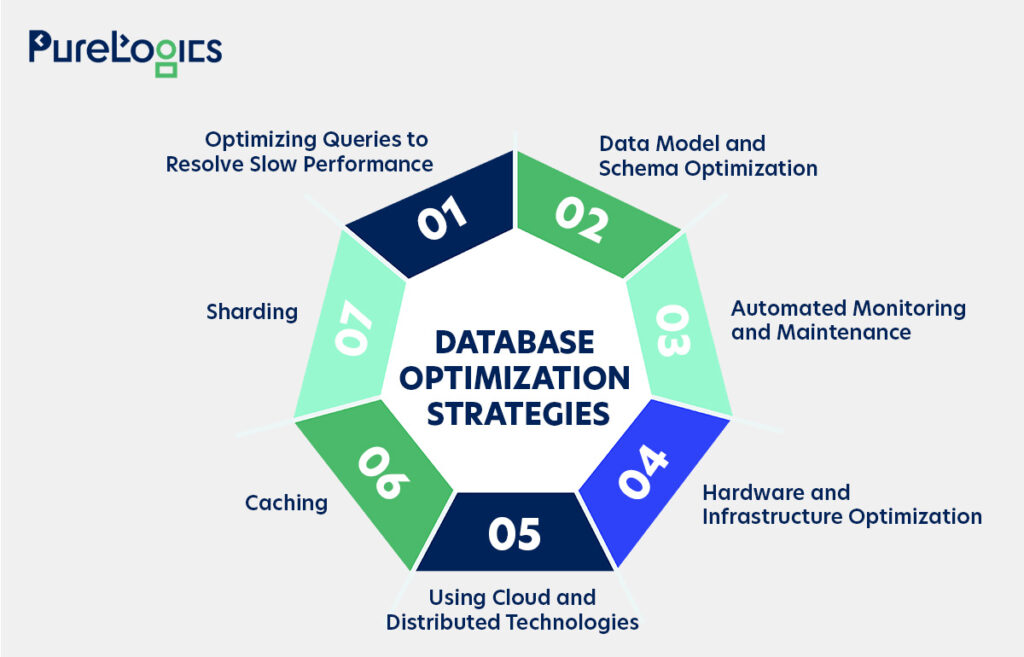
Below are the seven reliable strategies explained in detail that can help in effective database optimization.
1. Optimizing Queries to Resolve Slow Performance
In modern applications, even a small delay in database queries can affect user experience and system efficiency. Identifying and resolving slow queries early is critical for maintaining smooth operations under high traffic.
Problem: Slow Queries
Slow queries are database requests that take longer than expected to execute, impacting system performance. Common causes include:
- Inefficient joins or subqueries
- Missing or poorly designed indexes
- Retrieving unnecessary columns or rows
Solution: Query Optimization and Indexing
Once slow queries are identified, optimizing queries and applying the right indexes can dramatically improve performance.
Step 1: Identify Slow Queries
Use EXPLAIN or EXPLAIN ANALYZE to pinpoint slow queries:
EXPLAIN ANALYZE SELECT * FROM orders WHERE order_date > '2025-01-01';
Step 2: Analyze Execution Plan
Check table access type (full table scan, index scan), cost estimates, and expected rows. Example output:
Seq Scan on orders (cost=0.00..431.00 rows=10000 width=244)
Step 3: Refactor Query
Select only necessary columns and remove redundant joins:
- - Inefficient SELECT * FROM orders WHERE order_date > '2025-01-01'; - - Optimized SELECT order_id, customer_id, order_date FROM orders WHERE order_date > '2025-01-01';
Step 4: Create Indexes
Add indexes on frequently used columns in WHERE clauses or JOIN conditions to reduce query execution time:
CREATE INDEX idx_order_date ON orders(order_date);
Step 5: Re-run and Compare
Execute the optimized query after creating indexes to measure performance improvement:
- - Optimized query SELECT order_id, customer_id, order_date FROM orders WHERE order_date > '2025-01-01';
Before: Seq Scan, 10,000 rows
After: Index Scan, 500 rows
Step 6: Monitor continuously
Regularly monitor database queries and performance metrics using monitoring systems to ensure sustained efficiency and optimal performance. The tools you can use for monitoring are:
- Datadog
- Prometheus
Point to be noted: One important concern when applying indexing is to avoid over-indexing. While indexing improves query performance, having too many indexes can slow down write operations such as INSERT, UPDATE, and DELETE, since each index must also be updated whenever the data changes.
Example: Many e-commerce platforms use this strategy to handle the peak holiday traffic, like Amazon. The goal is to ensure that customers experience smooth browsing even during high-demand periods. They fine-tune customer queries and use indexing strategies to ensure that the platform stays responsive, supporting millions of users.
2. Data Model and Schema Optimization
The database structure remains efficient due to optimization of the schema, and this includes balancing table normalization, breaking down large tables into smaller, related sub-tables to improve data readability and reduce redundancy.
At the same time, balancing normalization with denormalization is best for maintaining both data integrity and performance. Moreover, the areas needing normalization can be identified by:
- Repeating groups (1NF): Multiple values stored in a single column.
- Partial dependencies (2NF): Non-key attributes depend only on part of a composite key.
- Transitive dependencies (3NF): Non-key attributes depend on other non-key attributes.
- High redundancy: Updating a value requires changing multiple rows.
- Frequent complex queries: Queries often join multiple columns or tables to retrieve a single piece of data.
Implementation: Normalization and Denormalization
- First Normal Form (1NF): Remove repeating groups, ensure atomic values.
- - Before 1NF CREATE TABLE Orders ( order_id INT, customer_name VARCHAR(100), product_1 VARCHAR(50), product_2 VARCHAR(50) ); - - After 1NF CREATE TABLE Orders ( order_id INT, customer_name VARCHAR(100), product_name VARCHAR(50) );
- Second Normal Form (2NF): Remove partial dependencies.
CREATE TABLE Orders ( order_id INT PRIMARY KEY, order_date DATE ); CREATE TABLE ProductsInOrder ( order_id INT, product_id INT, product_name VARCHAR(50), PRIMARY KEY(order_id, product_id) );
- Third Normal Form (3NF): Remove transitive dependencies.
CREATE TABLE Employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
dept_id INT
);
CREATE TABLE Departments (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50),
dept_location VARCHAR(100)
);
- Denormalization (selective): Duplicate data in read-heavy systems to improve performance.
CREATE TABLE CustomerOrdersSummary ( customer_id INT, customer_name VARCHAR(100), total_orders INT );
Pro Tip: Implement partitioning strategies to break down the extensive tables into smaller, more manageable segments to improve the query performance. Common approaches include Range partitioning (e.g., dividing data by date or time ranges) and List partitioning (e.g., separating data by categories or types).
Example: LinkedIn uses the denormalized schema to increase search speed across 1 billion users to ensure faster data retrieval when users do a search.
3. Automated Monitoring and Maintenance
Automated monitoring and maintenance is a critical data optimization technique. Continuous tracking of database performance and resource usage helps businesses identify bottlenecks, inefficient queries, and system constraints before they impact operations. This approach helps ensure that the database remains responsive, efficient, and scalable over time, enhancing overall data performance. Below are the three effective ways this can be done:
- Monitoring Tools: You can use platforms like New Relic, Prometheus, or cloud-native solutions to track query performance, system resources, and overall database health.
- Alerting & Anomaly Detection: You can set up alerts to identify unusual patterns or potential performance issues. This is important for databases hosted on AWS, GCP, or other cloud platforms, ensuring timely notifications before problems escalate.
- Predictive Maintenance with AI/ML: You can use AI/ML models to analyze historical usage patterns, automatically tune performance, and address potential system failures in advance. This helps maintain high availability and responsiveness, even during varying workloads.
4. Hardware and Infrastructure Optimization
Hardware tuning is important because even the most efficient queries and schemas can slow down if the underlying infrastructure cannot keep up. But by tuning disk I/O, memory, CPU, and network resources, businesses can ensure that data is retrieved, processed, and served as fast as possible.
This directly supports data optimization by reducing query execution times, lowering latency, and preventing resource bottlenecks. Here are four key strategies for optimizing hardware and infrastructure
- High-Performance Storage: Upgrade to SSDs or NVMe drives for faster data access, reducing delays in read/write operations.
- Memory Optimization: Make sure to allocate sufficient memory for frequently accessed data to minimize disk reads.
- Overloading: Avoid overloading and adjust the system’s concurrency settings to manage high traffic.
- Infrastructure Monitoring: Continuously track resource utilization (I/O, memory, CPU, and network) to detect and resolve bottlenecks before they impact queries.
Example: Netflix uses high-performance SSDs and optimized memory allocation to ensure its database is always ready to cater to the massive streaming demands. This hardware tuning is effective in minimizing latency and ensuring smooth video streaming.
5. Using Cloud and Distributed Technologies
Cloud-native solutions and distributed databases are necessary for modern data optimization because they offer flexibility and cost-efficiency. Moreover, the on-premises databases struggle with sudden traffic spikes, large datasets, and user demands. But moving to the cloud or adopting distributed systems, businesses can ensure high availability and reduce downtime. Here’s how this can be implemented:
- Cloud Services for Scalability: Implement platforms like AWS or Google Cloud to scale resources dynamically and manage demand fluctuations.
- Distributed Databases for Availability: Deploy solutions like Amazon Aurora or CockroachDB to distribute data across multiple geographical locations, ensuring optimal performance and availability during peak traffic.
- Serverless Databases for Flexibility: Adopt options like Aurora Serverless, Cloud Spanner, or PlanetScale for unpredictable workloads, ensuring automatic scaling while optimizing both cost and performance.
Example: Slack migrated to a cloud-enabled database architecture to manage its rapid growth. This transition allowed the company to scale easily without any compromise on performance and security.
6. Caching to Boost Performance
Caching can help reduce the load on your database and improve response times as the frequently accessed data is put into a memory store like Redis or Memcached. This helps to avoid data hitting the database repeatedly. Some of the effective caching strategies are:
- If queries like product info run frequently, then cache the results for a set time to prevent repetitive database hits.
- Consider caching the entire output of the high-traffic page to minimize queries altogether.
- Make sure that your cache does not serve the outdated data by implementing cache invalidation strategies like application-level caching (e.g., API responses), query-level caching, or materialized views.
7. Scale Horizontally: Sharding
With growth in database size and traffic, it becomes essential to maintain performance and avoid overloading a single server. Here, sharding can be a powerful optimization technique that mitigates this challenge by distributing data and queries across multiple servers.
Actually, sharding divides the large databases into smaller and manageable parts called shards, each hosted on a single server. This ensures the queries run faster, workloads are balanced, and the system scales without any hindrance as the volume of data increases. The reasons sharding can be used are to decrease query latency by spreading data across multiple machines, avoid bottlenecks by distributing read/write operations, and enable linear scalability, which helps support high traffic and data growth.
Here are the types of sharding:
- Range-Based Sharding: It splits database rows on a range of values, and then the database designer assigns the shard key to the respective range.
- Hashed Sharding: Here, the shard key is assigned to each row of the database by using a mathematical formula called a hash function. The hash function grabs the information from the row and produces a hash value. Furthermore, the application uses the value as a shard key and stores the information in the corresponding physical shard.
- Directory Sharding: It uses a lookup table to match database information to the corresponding physical shard, and a lookup table is like a table on a spreadsheet that links the database column to a shard key.
- Geo sharding: It splits and stores database information according to geographical location.
Now you know about the strategies, so it’s time to tell you about some data optimization tools.
Database Optimization Tools
Some of the tools that are effective in the optimization of databases are given below:
- Solar Winds Database Performance Analyzer: It analyzes the database 24/7, monitoring the processes of database optimization and performance.
- Datadog: It offers real-time monitoring of servers, databases, and various other tools and services across the IT infrastructure. Additionally, it provides visibility into application performance, enabling businesses to identify issues before they impact users.
- AWS Performance Insights: Integrated with Amazon RDS and Aurora, it provides performance tuning recommendations and detailed query analysis.
- EverSQL: It automatically optimizes SQL queries and monitors database performance for PostgreSQL and MySQL.
Below is the quick comparison of these tools for you:
| SolarWinds DPA | |
| Pros |
|
| Cons |
|
| Supported Databases | SQL Server, Oracle, MySQL, PostgreSQL, MariaDB, Aurora, IBM Db2, ASE |
| Datadog | |
| Pros |
|
| Cons |
|
| Supported Databases | PostgreSQL, MySQL, Oracle, SQL Server |
| AWS Performance Insights | |
| Pros |
|
| Cons |
|
| Supported Databases | Amazon RDS, Aurora |
| EverSQL | |
| Pros |
|
| Cons |
|
| Supported Databases | MySQL, MariaDB, PostgreSQL |
Even after implementing the strategies above and using tools, some of the common challenges you can come across are given below.
Challenges in Database Optimization
One of the best ways to improve database performance is by optimizing data, but implementing it effectively can be difficult. Some of the challenges you can come across are given below:
| Issues | Cause | Solution |
| Query Performance Issues | Inefficient queries, missing indexes, and poor query design | Refactor queries, use proper indexing, and analyze execution plans |
| Index Management | Incorrect index selection, over-indexing, and maintenance overhead | Choose optimal indexes, avoid over-indexing, and regularly maintain indexes |
| Complexity in Execution Plan | Difficulty in determining the optimal execution path | Use EXPLAIN/EXPLAIN ANALYZE, monitor query execution, and refactor heavy queries |
| Caching Challenges | Deciding what to cache, cache invalidation, and memory balancing | Implement proper caching strategies, use TTL, and invalidate cache on updates |
| Security vs Performance | Encryption, access control, and auditing slow down queries | Balance security with performance and consider selective encryption or indexing encrypted columns |
| Ongoing Maintenance Cost | Index rebuilds, vacuuming, and partitioning consume resources | Automate maintenance where possible and schedule off-peak optimizations |
| Connection Pooling Challenges | Poorly configured pools can exhaust connections and cause deadlocks, or slow queries | Configure pool size properly, monitor pool use, and recycle idle connections |
| CPU & Resource Utilization | High traffic or inefficient queries consume excessive CPU resources | Monitor CPU usage, optimize queries, scale horizontally or vertically, and adjust concurrency settings |
| Limits in Automation | Auto-tuning tools cannot handle complex real-world workloads | Combine manual tuning with automated tools and monitor continuously |
Wrapping Up
Data optimization is not just technically nice to have; instead, it is a critical success factor that directly impacts the user experience. Therefore, it is crucial to make the sluggish databases faster and high-performing. This helps in reducing the infrastructure costs and enhancing performance. However, you can come across challenges while optimizing your data, but beating these challenges and investing in optimization is worthwhile. Need expert guidance? PureLogics offers comprehensive database and backend services to help implement these optimization strategies with its experienced engineering team.
Book a 30-minute free consultation with us.
Frequently Asked Questions
What is an example of data optimization?
Its examples can include strategic decision making, operational efficiency, and storage optimization. This can include techniques like data cleaning, compression, and caching.
What is db optimization?
It is crucial for creating scalable and efficient systems that support business growth, and by using techniques like query tuning, schema optimization, and cloud solutions, companies can make their databases efficient to handle data demands easily.
What is the difference between query optimization and indexing?
Optimization is a broader term, whereas indexing is a specific optimization technique. The indexing speeds up the data retrieval by allowing the database to find the rows faster. Moreover, optimization includes how you structure joins, use filters, write subqueries, limit rows, and how the logic is organized with things like CTEs.

