 [tta_listen_btn]
[tta_listen_btn]
 November 6 2025
November 6 2025


The healthcare industry is confronting a striking paradox. On one hand, large language models (LLMs) promise to revolutionize clinical AI by streamlining diagnosis and assisting with documentation, etc. On the other hand, these models are also power-hungry. Globally, data centers are projected to double their electricity consumption to support AI workloads, growing from approximately 1.5% of global electricity use in 2024 to a significantly larger share by 2030. Within hospitals where there is no margin for downtime or failures, energy-efficient LLMs are essential. In this blog, we will compare traditional versus energy-efficient LLMs, examine why hospitals in particular need to adopt them, map out the practical steps for adoption, outline strategies to improve energy efficiency in clinical AI, and highlight critical considerations that hospital leaders must keep in mind.
First, let’s start with a comparison of traditional and energy-efficient LLMs.
Traditional vs. Energy-Efficient LLMs
Traditional LLMs can be more environmentally taxing than energy-efficient LLMs. Below is a comparison of the two models on key aspects, including deployment and sustainability.
| Aspect | Traditional LLMs | Energy Efficient LLMs |
|---|---|---|
| Model Size | Huge (billions of parameters) | Smaller or optimized (pruning, quantization) |
| Energy Use | High during training and inference | Lower, optimized for task and hardware |
| Performance | High (diminishing returns for specific tasks) | Comparable on specific tasks, better energy efficiency |
| Deployment | Requires heavy GPUs (Graphic Processing Units) / TPUs (Tensor Processing Units) | Best for lower-power environments |
| Sustainability | High carbon and energy footprint | Less environmental impact |
Furthermore, a research study by the University of Adelaide and the University of Reading, published in the Internal Medicine Journal, investigated the impact of artificial intelligence and found that LLMs processing thousands of patient records lead to significant resource consumption. The same study suggested that a single AI query uses enough electricity to charge a smartphone 11 times. In addition to cooling the servers, 20 milliliters of freshwater (per query) is consumed by data centers. In addition to energy consumption, hospitals require sustainable systems that ensure reduced operational costs and maintain high reliability under heavy workloads.
Reasons Hospitals Require Energy-Efficient LLMs
Energy-efficient LLMs impact operations and patient care by reducing energy use, which improves reliability and enables hospitals to scale AI safely. Below are some more ways in which energy-efficient LLMs improve healthcare systems
- System uptime: Reduce computational demand and decrease the risk of infrastructure overload, ensuring reliable AI support.
- Sustainability goals: Sustainable AI in healthcare helps cut emissions and meet ESG targets while showing responsibility to patients and regulators.
- Operational trust: Smaller, optimized models are easier to scale across departments or facilities without exceeding the hardware limit. While this improves reliability and efficiency, hospitals should be aware that some accuracy might be sacrificed compared to larger models, so careful validation is essential.
The reasons mentioned above demonstrate that energy-efficient LLMs are no longer a nice-to-have but a necessity. Therefore, healthcare leaders need to have a plan for effective adoption.
Future-Proof Your Hospital’s AI
Ready to cut costs, boost efficiency, and meet sustainability goals? Let’s build an AI strategy tailored for your hospital.
Roadmap for Hospitals Adopting Energy-Efficient LLMs in 2026
The roadmap below outlines key steps to optimize models, infrastructure, and ongoing performance for sustainable AI deployment.
Baseline Assessment
It is essential for healthcare providers to first assess or measure the current energy usage and computational demands of their AI models. This can include the following things:
- Average GPU/TPU use
- Latency and throughput
- Electricity consumption per inference
Additionally, establishing a baseline provides a clear understanding of where inefficiencies exist and sets reference points for evaluating the effectiveness of future optimizations. This helps further identify which models or workloads consume the most resources and should be prioritized for improvement.
Model Optimization
After establishing a baseline, hospitals can apply techniques to reduce the model size and computational requirements. This can include methods like distillation, quantization, and pruning (discussed later in this blog). Each method must be tested carefully to ensure that clinical operations and compliance are not compromised. The goal is to achieve a faster and more energy-efficient model while retaining most of its predictive performance.
Infrastructure Tuning
Energy-efficient models are most effective with the proper hardware and deployment strategy. Hospitals need to evaluate and select GPUs, TPUs, or other accelerators that deliver high performance at lower energy costs.
Tip: Hybrid setups that combine on-premises servers with cloud resources can help balance compute load and reduce energy consumption.
Continuous Monitoring
Hospitals should ensure ongoing monitoring of AI performance, energy usage, and key metrics to track power consumption, latency, accuracy, and the cost per inference. Continuous monitoring enables IT and clinical teams to identify anomalies, maintain reliable service levels, and assess the impact of subsequent updates.
Additionally, this helps support sustainability goals by ensuring that AI systems remain energy-efficient as workloads, patient volumes, or model updates change over time.
Strategies to Improve Energy Efficiency in Clinical AI Models
Hospitals can enhance AI energy efficiency using proven techniques given below, which are vital in balancing performance, speed, and accuracy.
Quantization in Healthcare AI
Quantization reduces the numerical precision in a model’s calculations, lowering the number of bits used to represent data. This reduces computation and lowers energy consumption while maintaining acceptable clinical performance.
Model Distillation
It is an effective technique to build smaller and faster AI models by training them to mimic larger and more accurate models. In a recent study titled “A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models,” a Knowledge Distillation (KD)-based approach was introduced to make AI models used in medical image analysis more transparent and explainable.
The researchers first trained a complex CNN (Convolutional Neural Network, a type of deep learning model) as a teacher. They then distilled their knowledge into a smaller and simplified student model that retained the main features while using a reduced number of layers. This lighter model was analyzed using feature map visualization to highlight how it makes decisions, giving clearer interpretability for clinicians. Furthermore, it was tested on three public datasets covering brain tumors, eye diseases, and Alzheimer’s. As a result, the model maintained strong classification accuracy with lower computational demands.
Overall, the results demonstrated that the distilled model offered faster and more intuitive visual explanations, with minimal performance loss.
Low-Rank Adaption (LoRA)
LoRA adapters are lightweight modules integrated into LLMs, enabling them to learn and adapt to new tasks without retaining all their parameters. They lower the computational and energy requirements for fine-tuning, which is essential in clinical settings where resources are often limited.
Pruning
This technique removes weights, neurons, or connections that contribute to the model’s performance. Furthermore, the elimination of redundant elements reduces the total number of computations required during both training and inference, lowering energy consumption and speeding up the response time. It also preserves most of the model accuracy while decreasing the hardware demands, helping hospitals deploy low-power AI models that are both sustainable and reliable.
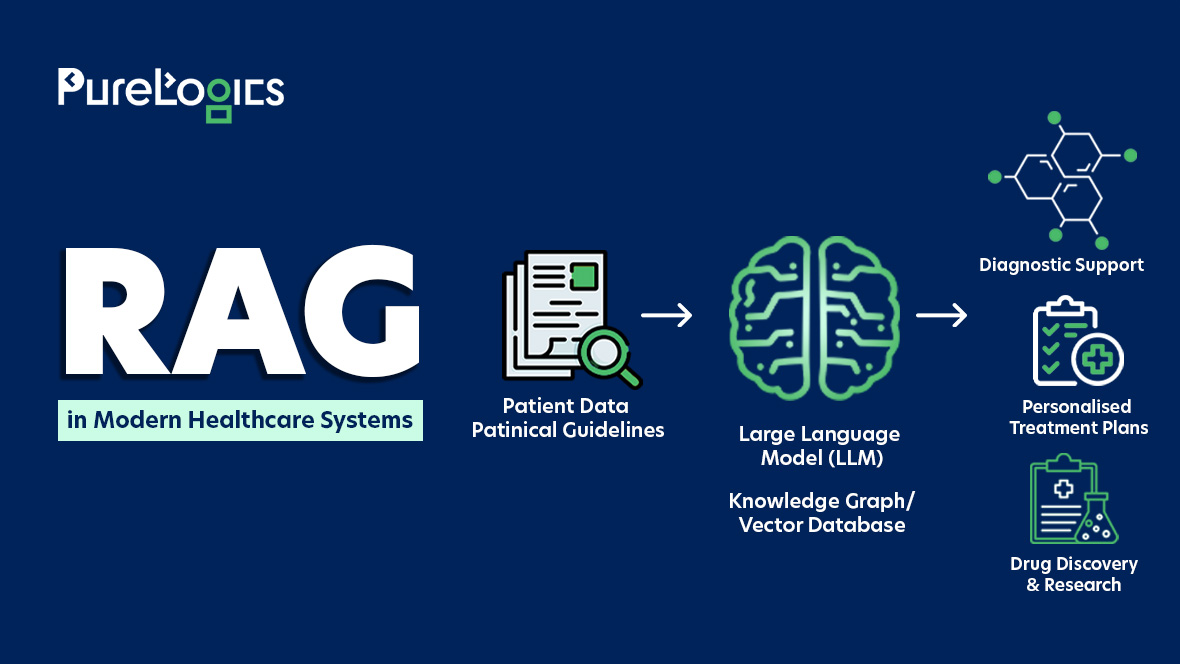
Retrieval Augmented Generation (RAG)
RAG is a method that links a language model with an external database, and rather than storing all knowledge within the model, it fetches relevant information from a structured source during runtime. This approach keeps the models smaller, uses less compute, and ensures they remain up-to-date.
Critical Considerations for Hospital Leaders
Hospitals can reduce expenses and carbon footprints by deploying energy-efficient LLMs, all while maintaining compliance and clinical reliability. Healthcare leaders should focus on three key areas:
- Practical deployment choices (hybrid models and modern GPUs) that can maximize efficiency while keeping the sensitive data secure.
- Performance tracking, which helps monitor clear metrics (cost per inference and latency) to ensure measurable ROI.
- Sustainability alignment is mandatory as it demonstrates responsible technology use to regulators, patients, and staff.
Preparing for Energy Efficient LLMs
Hospitals that plan for energy-efficient LLMs from the start can save money, decrease their environmental impact, and maintain their AI systems. So, it becomes possible to utilize advanced AI without overloading infrastructure or incurring additional costs. PureLogics can help healthcare providers optimize models and enhance performance in clinical AI systems with advanced generative AI services.
Book a 30-minute free consultation with our experts to see how you can adopt energy-efficient LLMs.
Frequently Asked Questions
How to make LLMs more energy efficient?
LLMs can be made energy efficient by optimizing their architecture and utilizing smaller, specialized models for specific tasks. Moreover, techniques like pruning, RAG can reduce computation, and LoRA can further reduce energy consumption.
Which is more energy-efficient for hospitals: on-premises or cloud-based LLMs?
Cloud-based LLMS are more energy efficient than on-premises deployments because cloud providers optimize hardware utilization, cooling, and energy sources. In contrast, on-premises setups often run at lower utilization and require dedicated cooling.
How to make LLMs cheaper?
Hospitals can reduce the cost of LLMs by utilizing cloud-based models to share infrastructure costs more effectively. Additionally, optimize prompt design to decrease token usage and fine-tune smaller, task-specific models instead of running a large, general-purpose one.