




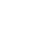 [tta_listen_btn]
[tta_listen_btn]
 February 3 2025
February 3 2025


Businesses rely on data lakes to analyze and store vast amounts of unstructured and structured data. A data lake lets you store data in raw form and implement different analytics and transformations to get meaningful insights. In this article, we’ll offer a detailed guide explaining how to build a scalable data lake with Databricks configured with AWS. This includes highlighting essential infrastructure, consuming data, transforming, and storing it in various layers while using Databricks tools for code execution.
Build a scalable data lake with Databricks and AWS.
Let PureLogics turn your data into powerful insights.
What is a Data Lake?
Data lakes are the primary repository for storing unstructured and structured data at any range. Atypical of traditional databases, a data lake leverages a schema-on-read methodology that helps you characterize the schema once you read the data instead of when you write the data. With this flexibility, data lakes are ideal for keeping diverse data types such as clickstreams, logs, social media data, etc.
What we will do
We will build a data lake by using AWS and Databricks. The procedure includes these steps:
Processing Data
We’ll process CSV files within an S3 bucket titled source-bucket-layer0. The bucket files will be included every other hour.
Scaling the S3 Bucket
Then, we’ll build the S3 bucket to Databricks and merge the various CSV files for showcasing.
Transforming Data
We’ll initiate preprocessing on the given data and then store the transformed data into a different S3 bucket titled silver-bucket-layer2.
Launching Silver Data
Then, we’ll supply the data from the above-mentioned layer 2, merge the CSV files into one DataFrame, and start further preprocessing to differentiate users into Inactive and Active.
Storing Gold Data
In the end, we’ll store all the pre-processes into a new bucket titled gold-bucket-layer3 and utilize a data catalog for performing metadata management.
A Step-by-Step Guide to Building a Scalable Data Lake
Step 1: Processing Data
CSV files will be included in the S# bucket known as source-bucket-layer0 after every hour. All these files have raw data that needs to be processed.
This procedure is performed using the Scheduler and Workflows to process the code.
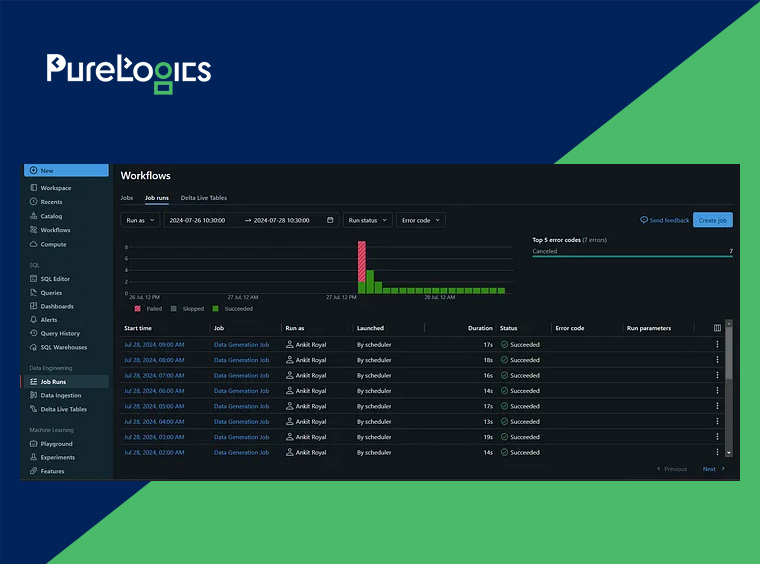
Through leveraging Create Job Interface, you can assign the job:
- Add Task Name
- Assign the roadmap by clicking path/of/the/notebook
- Job Cluster will be responsible for assigning the value to run the task
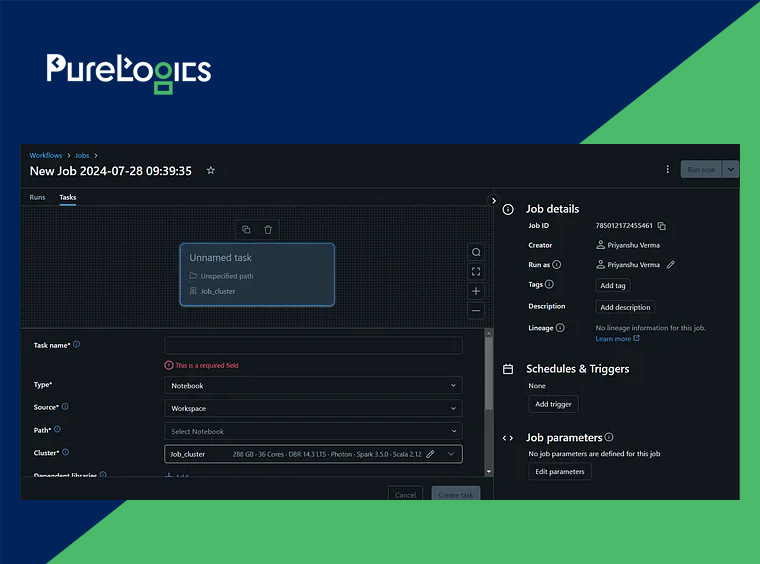
- There is an option “Add Trigger” at the right side interface to schedule time
Step 2: Scaling the S3 Bucket
Initially, we’ll scale the source-bucket-layer to the Databricks to get the CSV files.

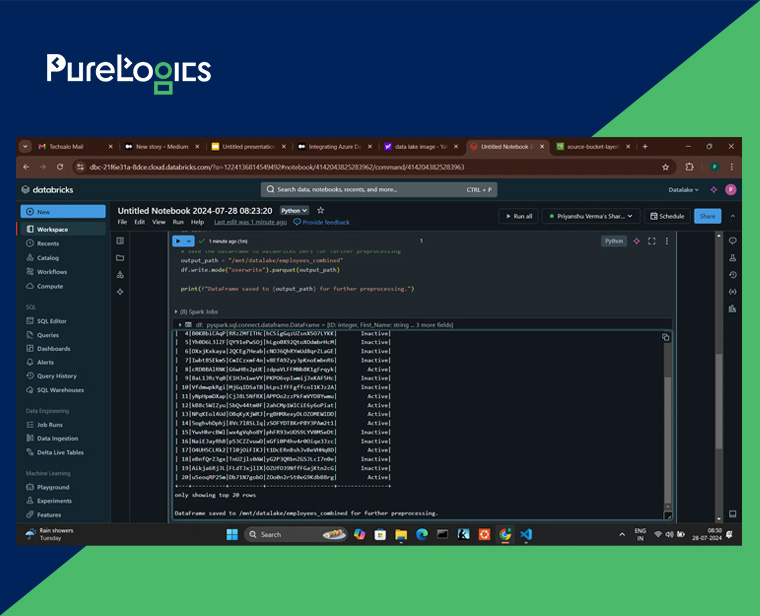
Step 3: Transforming Data
We will form a column status-numeric that sets a value of employees such as, 0 for “Inactive” and 1 for “Active” employees.

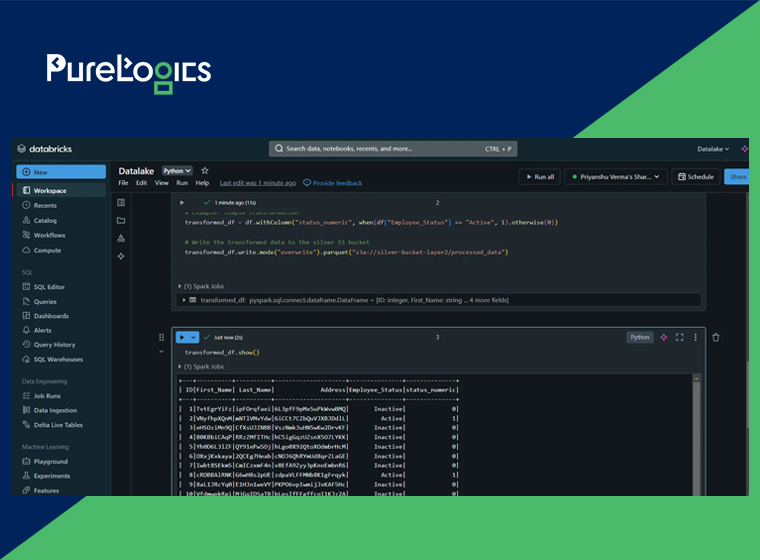
Step 4: Launching Silver Data
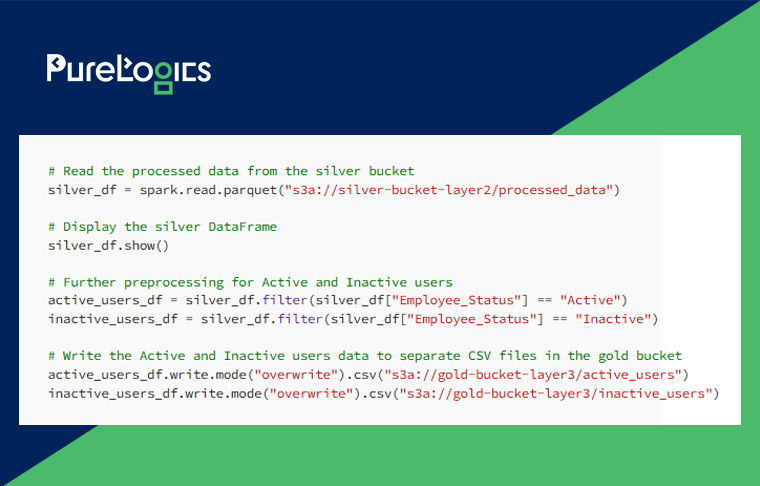
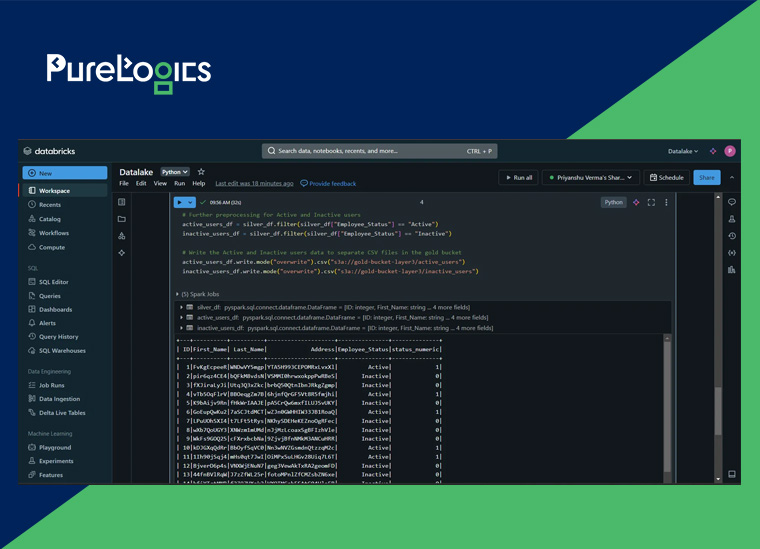
Step 5: Storing Gold Data
At last, we’ll store all the preprocessed data within the gold-bucket-layer3 and utilize a Unity Catalog for all the metadata management.
What is Unity Catalog?
It’s a Fine-Grained Data Governance Solution for available data in a data lake. The key reason for leveraging the Unity Catalog is that it assists in streamlining the security and also allows governance of the data by offering a centralized location where you can administer the reach to the data and review the data access.
The Unity Catalog architecture works like this:
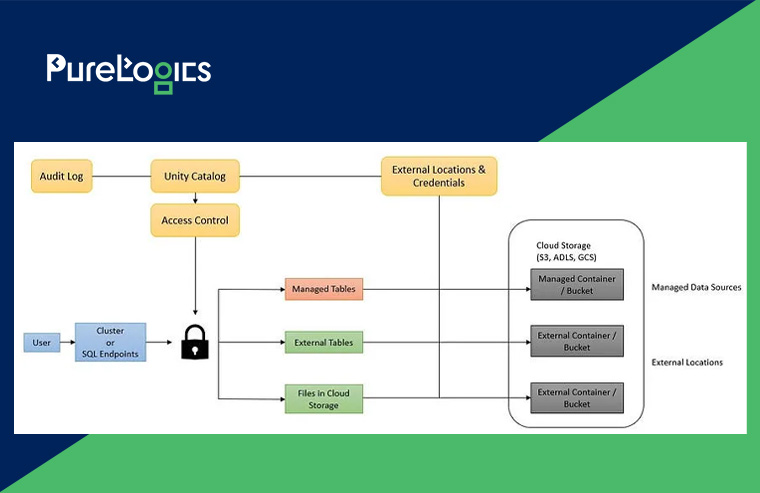
Coming back to storing gold data, here’s how it will go:

This code will form two tables within the Unity Catalog such as the inactive_users and active_users table:
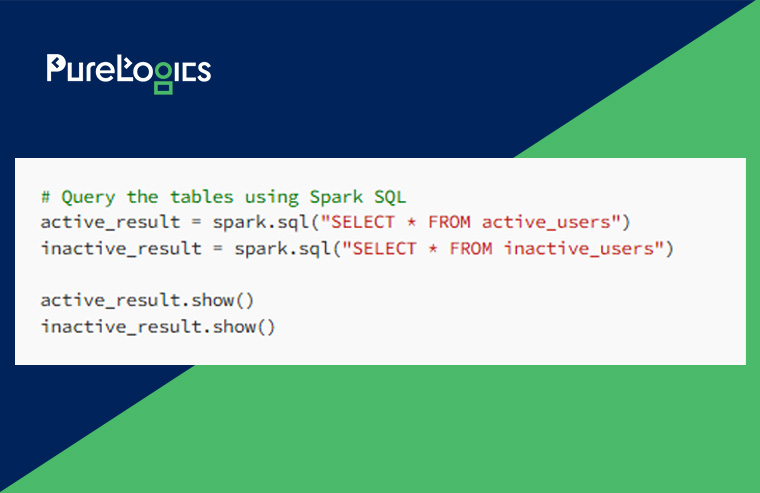
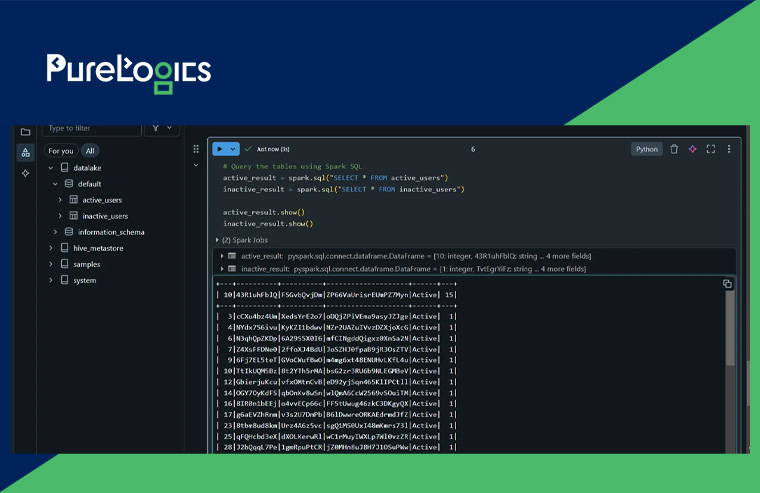
Conclusion
Creating a scalable data lake by using AWS and Databricks contains a number of well-defined steps that allow efficient data processing, transformation, storage, and also cataloging. We went through a comprehensive method to build a data lake, using AWS S3 for storing purposes and Databricks tools for code execution.
Processing: Raw data in CSV layout is processed into an S3 bucket named source-bucket-layer0 every 1 hour.
Launching: The S3 bucket is launched into the Fatabricks, allowing for smooth access and merging of CSV files.
Transformation: Data is modified by forming a column to classify employee status. The reformed data is stored within a secondary S3 bucket, e.g., silver-bucket-layer2.
Loading & processing: The reformed data is stacked from the silver bucket, sorted into inactive and active users, and then stored within a thor bucket named gold-bucket-layer3.
Cataloging: The ultimate preprocessed data is cataloged through Unity Catalog, offering subtle data governance and streamlining data access management and security.
By following all the mentioned steps, businesses can successfully analyze and manage large volumes of unstructured and structured data. This also helps get meaningful insights and ensure data security and governance.
PureLogics is a highly reliable AWS Select Tier services partner with 19+ years of experience+ in offering Amazon Web Services (AWS). Our expert team of engineers at PureLogics have the capability and right tools to solve complex Machine Learning and Data Engineering issues. Reach out to us to understand how to create these systems at scale!


