 [tta_listen_btn]
[tta_listen_btn]
 September 30 2024
September 30 2024


Distributed systems are composed of various interconnected nodes or components that coordinate and communicate with each other to achieve a common goal. Unlike old centralized systems, where all processing happens on one machine, distributed systems divide data and computation across numerous nodes, normally geographically dispersed.
- Such systems use networks to enable collaboration and communication across nodes, letting them work in parallel, share resources, and offer fault tolerance, scalability, and enhanced performance.
- Examples include distributed databases, peer-to-peer networks, content delivery networks, and cloud computing platforms.
Criticality of High Availability in Modern Distributed Systems
High availability is ascendant in distributed systems because of multiple key reasons:
Scalability
Distributed systems manage large volumes of data and traffic across various nodes. High availability allows these systems to scale dynamically to accommodate increasing demand while guaranteeing responsiveness to user requests and consistent performance.
Reliability
Customers expect distributed systems to be accessible and reliable at all times. High availability ensures that services are responsive and accessible at all times, providing trust among users and reducing the risk of downtime or service outages.
Fault Tolerance
These systems are inherently vulnerable to collapsing, including network partitions, software errors, and hardware failures. High availability mechanisms certify that even if one node fails, the system can continue functioning without significant disruption, ensuring uninterrupted service.
Disaster Recovery
Distributed systems typically span various geographical locations, making them vulnerable to regional network outages or disasters. High availability systems, like geographic redundancy, failure to alternative places, data replication, and maintaining continuous operations in case of sudden disruptions.
Business Continuity
Various distributed systems support crucial business operations, such as financial transactions, communication services, and e-commerce platforms. High availability is vital for ensuring organizational continuity and lowering the impact of disruptions on customer satisfaction, reputation, and revenue.
Competitive Advantage
In the competitive market, service interruptions or downtime can cause significant reputational damage and financial losses. High availability allows companies to differentiate themselves by offering resilient and reliable services, retaining and attracting customers in the future.
Key Architectural Strategies for Ensuring High Availability
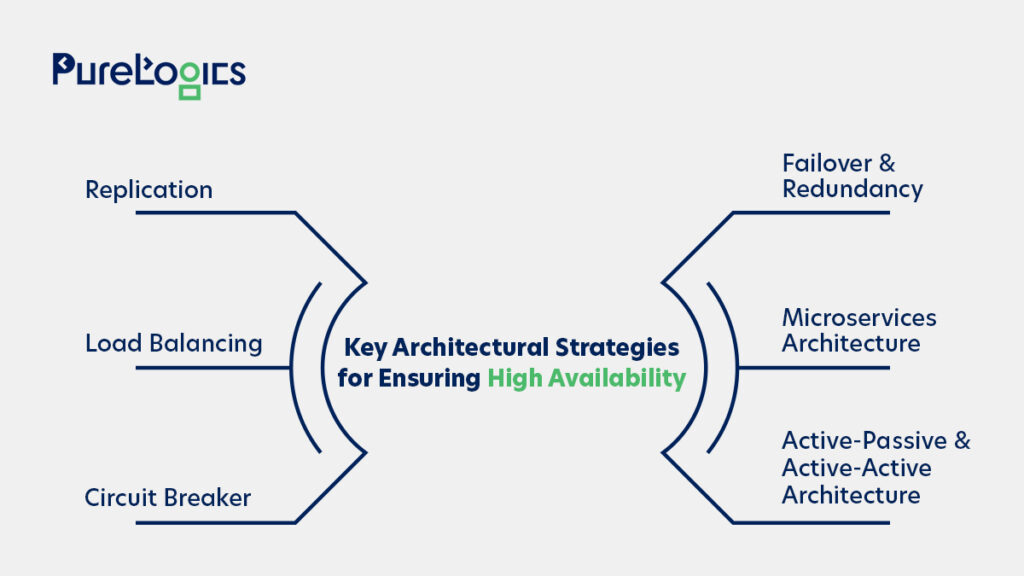
Architectural patterns that attain high availability are structures and frameworks that offer a base for creating systems capable of providing accessibility and continuous operation. These patterns contain multiple strategies and patterns aimed at mitigating failures, maintaining uninterrupted service, and minimizing downtime. A few common architectural patterns to get high availability are:
Replication
The replication pattern includes building duplicate copies of components or data across servers or nodes. By replicating services or data, the system can offer redundancy and withstand failures, ensuring that another component can take over immediately when one instance fails.
Load Balancing
This pattern divides incoming traffic among multiple resources or servers to avoid overloading any single node. By equally distributing workloads, load balancing improves performance, enhances resource utilization, and maintains scalability.
Circuit Breaker
This pattern is known as a fault tolerance pattern. It tracks requests to a service and opens automatically when a preset threshold is exceeded. This avoids cascading failures by temporarily halting requests to a failing service, giving it time to recover.
Failover & Redundancy
Failover and redundancy patterns include deploying redundant mechanisms and components that automatically switch to resources or backup systems when failures occur. These patterns maintain tasks and lower downtime by offering backup mechanisms that work as replacements in case of primary component failure.
Microservices Architecture
This architecture decomposes apps into loosely coupled, minor services that can be scaled and deployed independently. The microservices pattern enhances fault isolation, resilience, and scalability, ensuring simpler high availability within distributed systems.
Active-Passive and Active-Active Architecture
Active-passive architectures have active standby instances only when any primary instance fails, while active-active architectures contain numerous instances of the system actively offering traffic simultaneously. Both architectures provide fault tolerance and redundancy to get high availability.
Coordination & Communication Mechanism
Here are a few key mechanisms customized for high availability:
Replication Protocol
Use replication protocols like multi-master replication or primary backup to manage redundant data copies among multiple nodes. Replication protocols offer data synchronization and assure that updates are disseminated consistently to replicas, improving availability and fault tolerance.
Heartbeat Mechanism
Implement heartbeat mechanisms to track the nodes’ availability and health within the distributed systems. All nodes periodically send messages to alert their status, letting other nodes find network partitions or failures and start relevant recovery actions.
Quorum-based Consensus
Employ quorum-related consensus algorithms, such as Raft or Paxos, to align distributed nodes and settle agreement on data modifications or critical decisions. These systems ensure that many nodes meet before making changes, preventing data inconsistencies and enhancing fault tolerance.
Dynamic Load Balancing
Dynamic load balancing mechanisms divide incoming traffic and requests across nodes based on their health status and current capacity. Dynamic load balancers accommodate according to alternations in system conditions and route traffic to functional nodes automatically, improving availability and resource utilization.
Event-Driven Messaging
Use event-driven messaging systems such as AWS SNS or Apache Kafka to provide event propagation and asynchronous communication among distributed nodes. These architectures enable fault isolation and decoupled communication, improving system scalability and resilience.
Need High Availability for Your Distributed Systems?
Let our AI experts build scalable, reliable systems with built-in redundancy and failover capabilities.
Operational Guidelines for Sustaining High Availability in Distributed Systems
Operational best guidelines for high availability within distributed systems contain various procedures and strategies to ensure fault tolerance, resilience, and continuous operations. Here are the top key practices:
Automated Alerting & Monitoring
Integrate robust monitoring software to continuously monitor resource utilizations, system performance, and health metrics among distributed nodes. Set up automated alerts to notify operations of anomalies or issues, allowing proactive intervention and lowering downtime.
Auto-Scaling & Capacity Planning
Conduct regular capacity planning assignments to predict workload demands and expand distributed resources accordingly. Use auto-scaling mechanisms to adjust resource allocation dynamically based on real-time metrics, ensuring optimal availability and performance during peak usage.
Runbooks & Documentation
Manage runbooks detailing operational processes, up-to-date documentation, incident response protocols, and system architectures. Document regular troubleshooting stages, escalation paths, and recovery procedures to streamline tasks and offer knowledge sharing across teams.
Backup and Disaster Recovery
Build detailed disaster recovery plans highlighting processes for data backup, failover, and replication. Create cloud regions or secondary data centers to replicate critical services and data, allowing rapid recovery in case of disasters or catastrophic failures.
Regular Validation & Testing
Organize regular load, failover, and performance testing to validate distributed systems’ high availability and resilience. Utilize chaos testing and synthetic monitoring to find potential weaknesses and simulate real-world circumstances before they affect production.
Challenges in Building High-Availability Systems
Obtaining high availability comes with numerous challenges that companies should address:
Complexity
Integrating distributed architectures, automated failover mechanisms, and redundant components boosts system management and design complexity. Maintaining an available infrastructure demands specialized tools, expertise, and skills.
Cost
Creating and managing high-availability infrastructure is extremely costly, as it normally involves investing in network infrastructure, disaster recovery facilities, and redundant hardware. Furthermore, integrating failover mechanisms and automated monitoring might require additional investments in resources and tools.
Performance Overhead
Introducing failover and redundancy mechanisms can allow performance overhead, including processing overhead or growing network latency for replication. Balancing high availability needs with performance factors is essential to ensure maximum system performance.
Dependency Management
These systems often depend on various interconnected services and components. Ensuring compatibility and managing dependencies between multiple libraries and software versions can be difficult, especially within complex distributed architectures.
Consistency & Synchronization
Managing data consistency among distributed systems can be difficult, especially with distributed databases or active-active replication. Ensuring that copies of data remain consistent and synchronized requires careful coordination and planning.
Concluding Thoughts
With technological advancement, new trends impact system design and high availability. AI is rapidly being used in system designs to achieve high availability. PureLogics has 19+ years of experience in AI and offering cloud services. We can provide built-in redundancy, automated failover capabilities, and scalable infrastructures, allowing companies to build high availability without needing major upfront capital investments.
Getting high availability in a distributed database is an ongoing problem that requires a combination of strategic planning, fundamental principles, and key strategies for effective implementation. Let our experts handle these challenges. Give us a call today!