




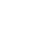 [tta_listen_btn]
[tta_listen_btn]
 January 13 2025
January 13 2025

As organizations rush toward digital transformation, the challenge is to handle large volumes of data, and the worth of that information fades over time. The difficulty is to evaluate, learn, and interpret real-time information to detect anomalies, get accurate outcomes, and predict future states.
We’ll talk about the architecture for a service that can get real-time inference on any streaming data—furthermore, the Amazon Kinesis Data Analytics with Apache Flink to independently evoke any underlying databases or services.
In-stream data that is managed in real-time is hard to understand, so let’s break it down into two categories:
- Real-time inference is the capability to utilize information from the feed to the future state of the project for the fundamental data.
- Instream data means the ability to process a stream of data that gathers, analyzes, and processes information.
Assume a streaming app that gathers credit card transactions with a few other parameters, including source IP, to get the geographic details of the amount and transaction. This information is later used to conclude fraudulent transactions immediately if you compare this to a traditional batch-oriented approach that finds fraudulent transactions after the end of the business day and produces a report when time has passed.
Real-Time In-Stream Inference Architecture
Let’s talk about leveraging Amazon Kinesis Data Analytics for Apache Flink (KDA), Amazon SageMaker, Apache Flink, and Amazon API Gateway to tackle challenges like real-time fraud detection on streaming credit card transactions. We outline how to build a reliable, scalable, and highly available streaming architecture using managed services, significantly reducing operational overhead compared to managing your infrastructure. We focus on setting up and executing Flink applications using KDA for Apache Flink.
The data is fed to the Kinesis Data Streams utilizing the Amazon Kinesis Producer Library in the architecture. You can use any KDS-supported ingestion pattern. KDS streams this data to an Apache Flink-based KDA application, which manages the necessary infrastructure, scales based on traffic patterns, and automatically handles failure recovery. The Flink application is set up to call an API Gateway endpoint using Asynchronous I/O. This API Gateway is connected to an AWS SageMaker endpoint, though you could use any suitable endpoint for your data enrichment needs. Flink distributes the data across multiple stream partitions, and user-defined operators can transform the data stream.
Revolutionize Real-Time Data
Use the power of SageMaker, Flink, and Kinesis for seamless insights.
Apache Flink
This is an open-source distributed processing framework built for stateful computations on both bounded and unbounded datasets. This architecture utilizes KDA and Apache Flink for in-stream analytics and employs an Asynchronous I/O operator to interact with external systems.
Apache Flink and KDA
KDA for Apache Flink is a fully managed AWS service that allows you to use Apache Flink for processing streaming data. You can use Scala and Java with KDA to examine data streams. The service handles the underlying infrastructure, including tasks like provisioning compute resources, parallel computation, scaling, and backing up your applications via checkpoints and snapshots.
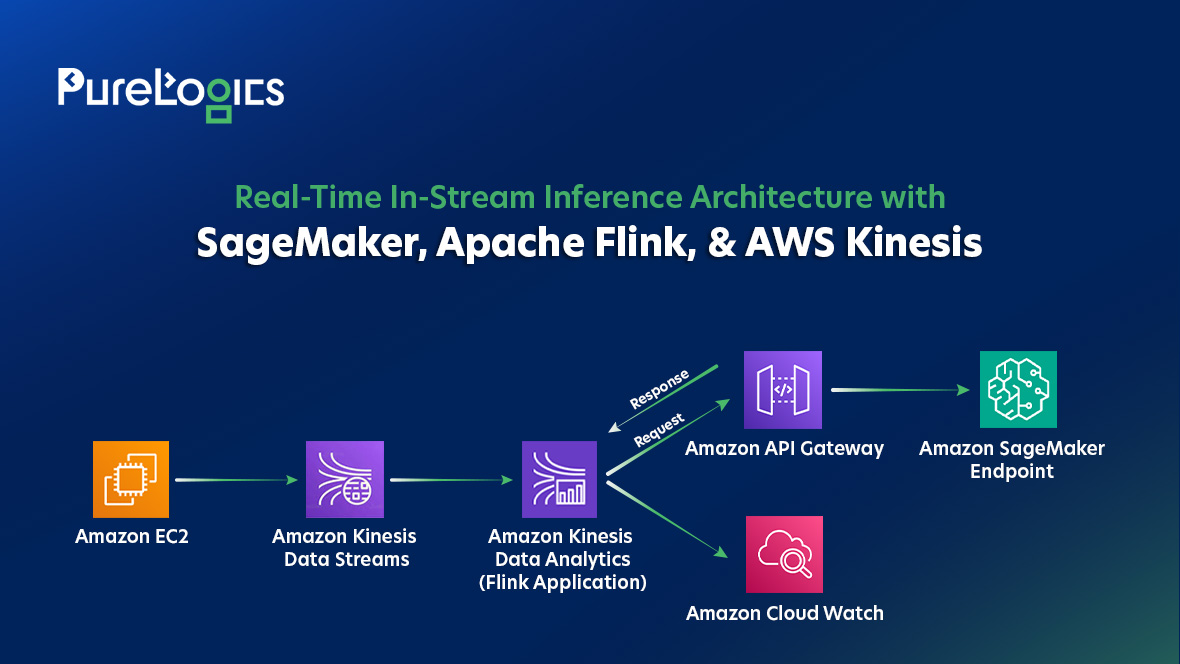
Asynchronous I/O Operator of Flink
The asynchronous I/O operator in Flink enables interaction with external systems to enrich stream events or perform computations asynchronously. This operator allows a single parallel function to handle multiple requests and responses simultaneously, often boosting streaming throughput. The Asynchronous I/O API integrates smoothly with data streams, handling concerns like order, event time, and fault tolerance. You can configure it to call external databases or APIs, like the architecture that uses API Gateway integrated with SageMaker endpoints.
Where does Amazon SageMaker Stand
In this architecture, there’s an Amazon SageMaker endpoint being used to identify fraudulent transactions through API Gateway. Amazon SageMaker is a fully managed service that enables developers and data scientists to build, train, and deploy machine learning (ML) models quickly. SageMaker streamlines the ML process, making it easier to develop high-quality models, which can then be deployed for real-time inferences.
You can create persistent endpoints with SageMaker to receive predictions from models deployed through SageMaker hosting services.
Getting Started with AWS
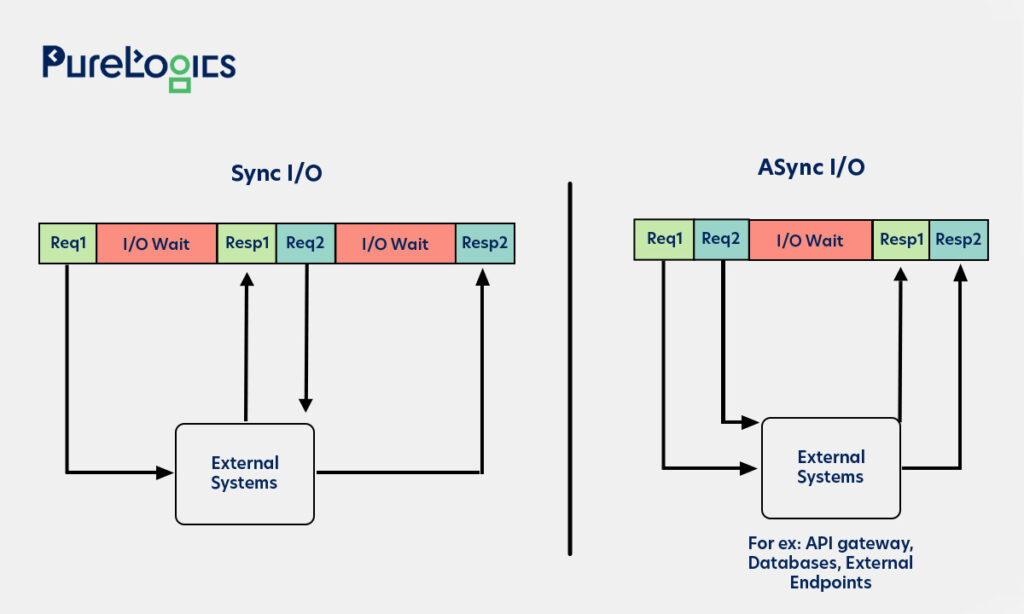
To help you jumpstart the process, AWS offers the AWS Streaming Data Solution for Amazon Kinesis (Option 4), a pre-built solution available as a one-click CloudFormation template. You can then structure a real-time inference pipeline within a few minutes. While the solution leverages AWS Lambda, it can easily be modified to use SageMaker, replicating the architecture described in this post. There is also an AWS Solutions Construct that connects an API Gateway to a SageMaker endpoint, which can replace Lambda in the setup. For more information, check the solution’s implementation guide.
The diagram below showcases the architecture of this solution.
Conclusion
In this post, we outlined an architecture that uses Kinesis Data Streams (KDS), Kinesis Data Analytics for Apache Flink (KDA), Apache Flink, and Amazon SageMaker to build a highly available and scalable real-time inference application. Using managed services like these means you don’t need to worry about provisioning or maintaining infrastructure—letting you focus on deriving insights and running real-time inferences from your data streams.
AWS Streaming Data Solution for Amazon Kinesis offers a better way to automatically implement the key AWS solutions to find, store, process, and infer from streaming data.
PureLogics has in offering manageable and scalable AWS cloud solutions. Contact us today!




