




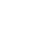 [tta_listen_btn]
[tta_listen_btn]
 September 8 2025
September 8 2025


A vector database stores data as vectors, which are numerical representations of complex objects, such as text, images, or graphs. If you already know the basics and want to explore further, this blog will take you beyond definitions to help you truly understand how vector databases work and why they matter.
Key Takeaways
- How do vector databases work?
- Which are the top vector databases?
- How do these top vector databases work (architecture)?
- What are their pros and cons?
- What is the future of vector databases?
- How to choose the right vector database?
Bonus: We provide code snippets for each of the top vector databases to help you get started, along with pricing information for each included.
Let’s begin with the explanation of vector databases.
What Are Vector Databases?
It is a specialized database that stores information as multi-dimensional vectors (also known as embeddings), which represent specific features or attributes of information. These vectors can range from a few dimensions to thousands, depending on the complexity of the data being processed. This data can be text, images, audio, and video, which can be converted into vectors using various processes like machine learning models, word embeddings, or feature extraction methods/ techniques.
How Vector Database Works?
These databases represent a shift away from traditional databases and have evolved in response to the need for storing and processing data types and vectors. Let us break down how a vector database operates:
- Input data: Various formats like images, documents, videos, audio, and structured/unstructured data are fed into the systems
- Embedding conversion: An embedding model changes this diverse data into numerical vector representations that contain the semantic meaning and relationships.
- Database storage: These vector embeddings are stored in a specialized vector database that utilizes mathematical distance calculations to identify similar items based on vector proximity, rather than exact matches.
Here’s the pictorial representation of vector databases’ work:
For instance, if a user searches for an image of a golden retriever, the vector database will return pictures of dogs with similar features (such as fur color, shape, and size) to the query image. However, in a text-based search, if a user enters “how to bake chocolate cake,” the vector database will return recipes or articles that match the user’s intent, even if the exact words differ (such as “chocolate sponge recipe” or “steps to make a cocoa cake”).
Given these capabilities, numerous vector databases have emerged to meet different needs. Each solution offers various features, and below are the top 5 vector databases as promised in the key takeaways above:
Top 5 Vector Databases
Here are the top five vector databases, each with distinct strengths to help users meet the specific needs of their projects.
1. Weaviate
Weaviate is an open-source vector database that enables users to store data objects and ML model embeddings with the ability to scale billions of records. It is ideal for scenarios such as enterprise search, question-answering, or any app requiring AI-driven insights over complex data, where users might vectorize images or text and link them to symbolic knowledge (concepts and attributes). Stack AI and Instabase are among the popular names using it.
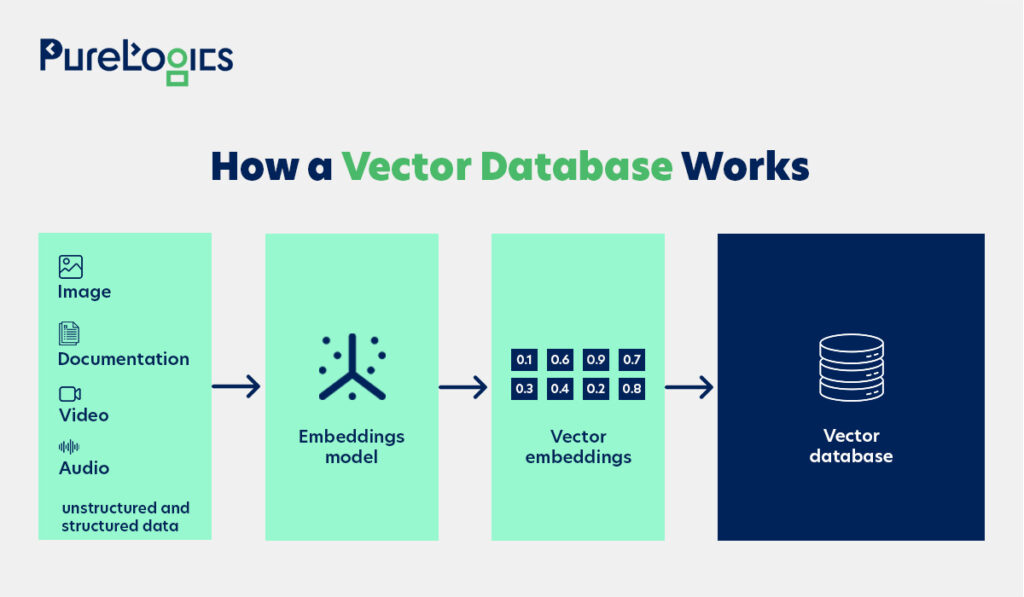
Moreover, it supports multiple deployment models, including self-hosted, managed, and hybrid options, giving flexibility based on infrastructure needs. Below is the pictorial representation of how Weaviate works:
- It works by taking data (such as text or images) and converting it into numerical vectors called embeddings.
- Then stores these embeddings and their original data. So when the search is performed, it compares the vector of your query to the stored vectors to find the most similar ones and returns the corresponding original data.
Let us tell you about its pros and cons:
| Pros | Cons |
| Supports AI use cases with semantic search capabilities | Needs infrastructure management and scaling |
| Facilitates hybrid search (vector+ keyword), making it highly flexible | May not perform well with massive datasets |
| Integrates with multiple ML models and frameworks for custom vectorization | Less mature than established solutions like Pinecone |
| Enables a schema-based approach, making it easy to handle relationships between objects and metadata. | Needs substantial computational resources |
| There is no vendor lock-in like some of its competitors | Incorporating it into existing systems or workflows may present difficulties. |
The code below can help you create a collection, insert embeddings, and run similarity searches with metadata filtering. Replace documents or query to view how semantic search works with your own dataset.
<style>
.wp-block-table table {
border-collapse: collapse;
width: 100%;
table-layout: fixed; /* Forces equal column widths */
}
.wp-block-table td {
width: 50%; /* Equal width for both columns */
padding: 10px;
text-align: left;
background: #ffffff; /* Default white background */
word-wrap: break-word; /* Prevent overflow if text is long */
}
/* First row styling */
.wp-block-table tr:first-child td {
text-align: center;
background: #f0f0f0; /* Light grey background */
font-weight: bold;
}
</style>
<figure class="wp-block-table">
<table>
<tbody>
<tr>
<td><strong>Pros</strong></td>
<td><strong>Cons</strong></td>
</tr>
<tr>
<td>Supports AI use cases with semantic search capabilities</td>
<td>Needs infrastructure management and scaling</td>
</tr>
<tr>
<td>Facilitates hybrid search (vector+ keyword), making it highly flexible</td>
<td>May not perform well with massive datasets</td>
</tr>
<tr>
<td>Integrates with multiple ML models and frameworks for custom vectorization</td>
<td>Less mature than established solutions like Pinecone</td>
</tr>
<tr>
<td>Enables a schema-based approach, making it easy to handle relationships between objects and metadata.</td>
<td>Needs substantial computational resources</td>
</tr>
<tr>
<td>There is no vendor lock-in like some of its competitors</td>
<td>Incorporating it into existing systems or workflows may present difficulties.</td>
</tr>
</tbody>
</table>
</figure>Weaviate offers three models: the first is a serverless cloud, which is $25 per month. The next is enterprise cloud, with pricing starting at $2.64 per AI Unit. Lastly, BYOC (Bring Your Own Cloud) enables users to run Weaviate within their own VPC, with customized pricing tailored to meet their specific enterprise needs.
2. Pinecone
Pinecone is built for scalability, handling millions of vectors with low-latency search, and follows a fully managed serverless deployment model, meaning developers don’t have to worry about infrastructure. Additionally, in terms of scalability, it is designed to handle billions of vectors while maintaining fast query response times (low latency).
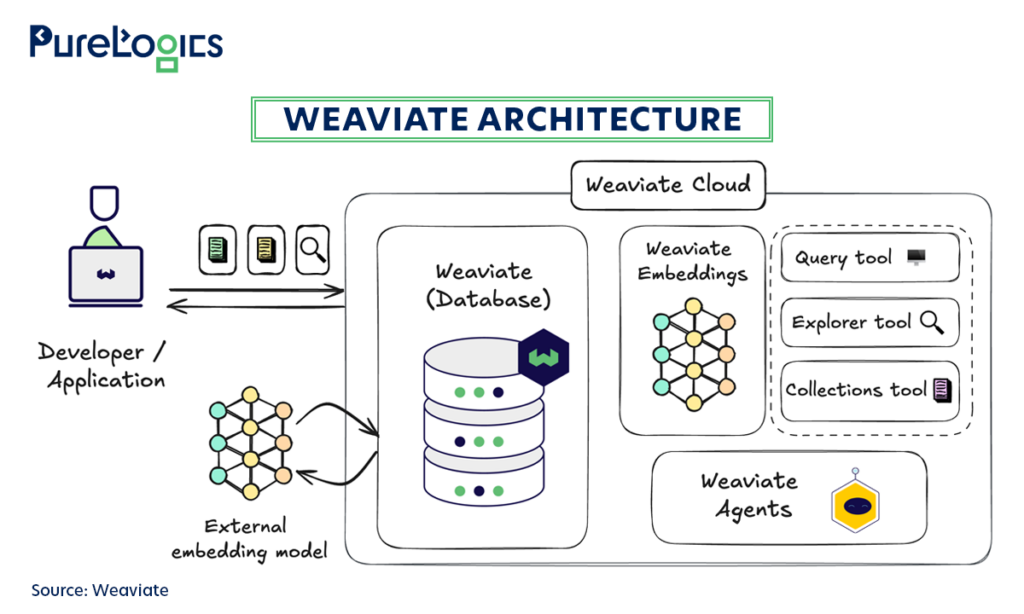
Due to its efficiency, some notable companies like CustomGPT.ai use it, so let us tell you about its basic working:
- Developers can start by ingesting high-dimensional vector data, such as images and text, into Pinecone.
- Then Pinecone efficiently indexes the incoming vector data, allowing the storage vectors in a way that facilitates efficient retrieval and search.
- When a user submits a query, Pinecone compares it to the indexed vectors. It utilizes customizable ranking algorithms and similarity metrics to identify vectors that match the query the most closely.
Let us tell you about the pros and cons of Pinecone:
| Pros | Cons |
| Manages all the technical setup and maintenance automatically. | Gets costly when scaled to handle large amounts of data |
| Handles large volumes of data and queries | Limited control over certain optimizations |
| Easy documentation and simple APIs | Offers a restricted ability to move or migrate |
| Built-in features for AI/ML applications | Lacks some advanced querying capabilities that some projects require |
| Quickly finds and retrieves vectors. | Vendor lock-in due to proprietary managed service |
You can copy and paste this code snippet to insert embeddings for your document into Pinecone, allowing you to query similar items instantly. Furthermore, you can also modify documents or queries to test semantic search on your data, without setting up servers.
import pinecone
import numpy as np
from sentence_transformers import SentenceTransformer
# Load model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Initialize Pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="us-east1-gcp")
index = pinecone.Index("example-index")
# Example data
documents = ["car", "automobile", "dog"]
vectors = [(str(i), model.encode(doc).tolist()) for i, doc in enumerate(documents)]
index.upsert(vectors)
# Query
query_result = index.query(vector=model.encode("car").tolist(), top_k=2)
print(query_result)The starter plan is free for Pinecone, and the Standard plan starts at $50 per month with pay-as-you-go usage (features like support and backup/restore are included). However, the enterprise plan starts at $500/month, offering mission-critical capabilities such as audit logs, a 99.5% uptime SLA, HIPAA compliance, and private networking.
The next tool we have is Chroma, which is an open-source embedding database.
3. Chroma
It is an embedding database that simplifies the development of LLM applications by facilitating easy integration of external knowledge and capabilities. Chroma excels in developing conversational AI, document memory, and recommendation prototypes. In terms of scalability, it works best for small to medium-sized workloads.
Moreover, its open-source deployment model makes it highly developer-friendly for prototyping. Below is the simplified pictorial representation of Chroma architecture:
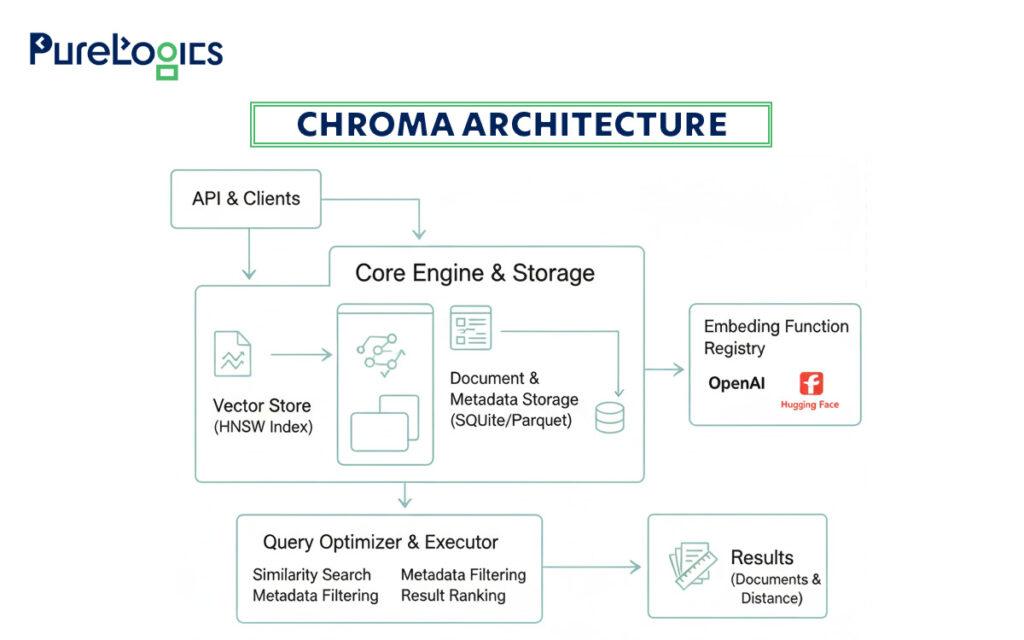
The Chroma architecture is built to be a fast and efficient vector database, and here is how it works:
- Its API handles requests, while the Core Engine manages both a Vector Store for numerical embeddings and a separate Document Store for the original data.
- The system automatically converts text to embeddings using a Registry of powerful models.
- Query Optimizer finds and ranks the most relevant results, ensuring quick and accurate responses.
Now that you know about its architecture, it’s time to discuss its pros and cons.
| Pros | Cons |
| Efficient storage and querying of embeddings with minimum setup | Limited scalability in comparison to Pinecone or Milvus |
| Works well with ML/AI frameworks and embedding models | Lacks features like hybrid search or strong metadata handling |
| Supports experimenting and testing without cloud dependency | Smaller ecosystem in contrast to Weaviate, Pinecone, and Milvus |
| Easy to use for Python developers | Fails to meet heavy enterprise deployment needs |
Below is a Python snippet for storing and querying embeddings efficiently, and you can use it for building semantic search, content recommendations, or similarity matching in small projects and prototypes.
import chromadb
# Initialize Chroma client
client = chromadb.Client()
# Create a new collection
collection = client.create_collection(name="example")
# Add some embeddings (dummy vectors here for illustration)
collection.add(
ids=["1", "2", "3"],
embeddings=[[0.1, 0.2, 0.3], [0.15, 0.25, 0.35], [0.9, 0.8, 0.7]],
metadatas=[{"text": "car"}, {"text": "automobile"}, {"text": "dog"}]
)
# Query the collection with a sample embedding
results = collection.query(
query_embeddings=[[0.12, 0.22, 0.32]],
n_results=2
)
print(results)The best part is that it is free to start, and users only have to pay for usage (includes 10 databases). For teams $250 per month, with $100 credits (supporting up to 100 databases). Moreover, custom pricing is available for enterprises that offer unlimited databases and team members. Before you make your decision, let us tell you about its pros and cons:
The third is Weaviate, which is a popular choice for beginners and advanced AI application development.
4. Milvus
It is an open-source vector database designed for production environments, specifically built to handle massive AI workloads such as recommendation systems, video/image search, and large-scale vector corpora. Milvus is a highly scalable system that supports billions of vectors, featuring indexing, partitioning, and fault tolerance. The popular names using it are Walmart, Shell, Robolox, Salesforce, and AT&T.
In terms of deployment, Milvus can run self-hosted, in Kubernetes clusters, or via Zilliz Cloud (its fully managed service). Here’s the pictorial representation of how Milvus works:
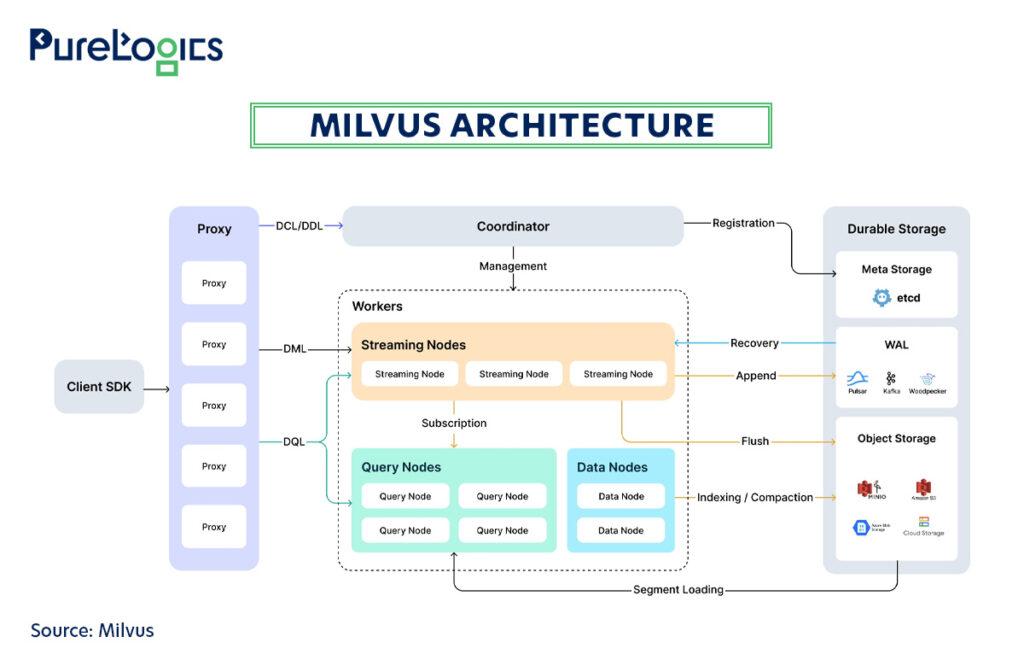
The system is composed of four main layers:
- The access layer, which consists of proxies that are the entry point for user requests, handles validation and load balancing.
- The next is the coordinator, which acts as the “brain,” managing the cluster topology, scheduling tasks, and ensuring data consistency.
- Then, there are worker nodes, which are the workhorses of the system, comprising three types: Streaming nodes for processing new data, Query Nodes for searching historical data, and Data Nodes for offline tasks such as indexing and compaction.
- The storage layer, which serves as the foundation for data persistence, comprises Meta Storage for metadata, a Write-Ahead Log (WAL) for capturing real-time data changes, and Object Storage for storing index files and log snapshots.
Furthermore, it integrates with well-known AI tools and offers enterprise features such as replication and backups, giving it an edge in high-volume data use cases. Let us tell you more about its pros and cons:
| Pros | Cons |
| Handles large-scale and high-dimensional data | Users have to deploy, manage, and scale infrastructure |
| Supports integration with cloud storage solutions like AWS S3 | Self-hosted, which means it requires more operational effort |
| Provides a variety of index types and algorithms (e.g., HNSW, IVF) | Getting optimal performance may require tuning of parameters |
| Integrates strongly with other AI and ML tools | |
| Large and active community |
The code below can help you connect to Milvus, generate a collection, insert sentence embeddings, and run a cosine similarity search to find the closest match.
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
documents = ["car", "automobile", "dog"]
# Connect to Milvus
connections.connect("default", host="localhost", port="19530")
# Define schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384)
]
collection = Collection("example_collection", CollectionSchema(fields))
# Insert data
vectors = [model.encode(doc).tolist() for doc in documents]
ids = list(range(len(documents)))
collection.insert([ids, vectors])
# Search
results = collection.search([model.encode("car").tolist()], "embedding", {"metric_type": "COSINE"}, limit=2)
print(results)Milvus offers multiple pricing options depending on the user’s deployment preferences. For instance, the open-source version is entirely free, whereas the Zilliz Cloud managed service starts at $99 per month for dedicated tiers. Moreover, enterprises can obtain customized costs based on vCU consumption, storage requirements, and support level needs.
5. Qdrant
Used by popular names like HubSpot and TripAdvisor, Qdrant is ideal for building vector search and recommendation systems that require fast, accurate, and scalable similarity searches. It is designed for high scalability, handling millions of vectors efficiently and supporting distributed clusters to manage growing datasets without compromising performance. Moreover, developers also select it when they need speed at scale with up-to-the-second data updates in their ML apps, as a self-hosted solution on their own infrastructure or via a managed cloud service. Below is a pictorial representation of the high-level architecture of Qdrant.
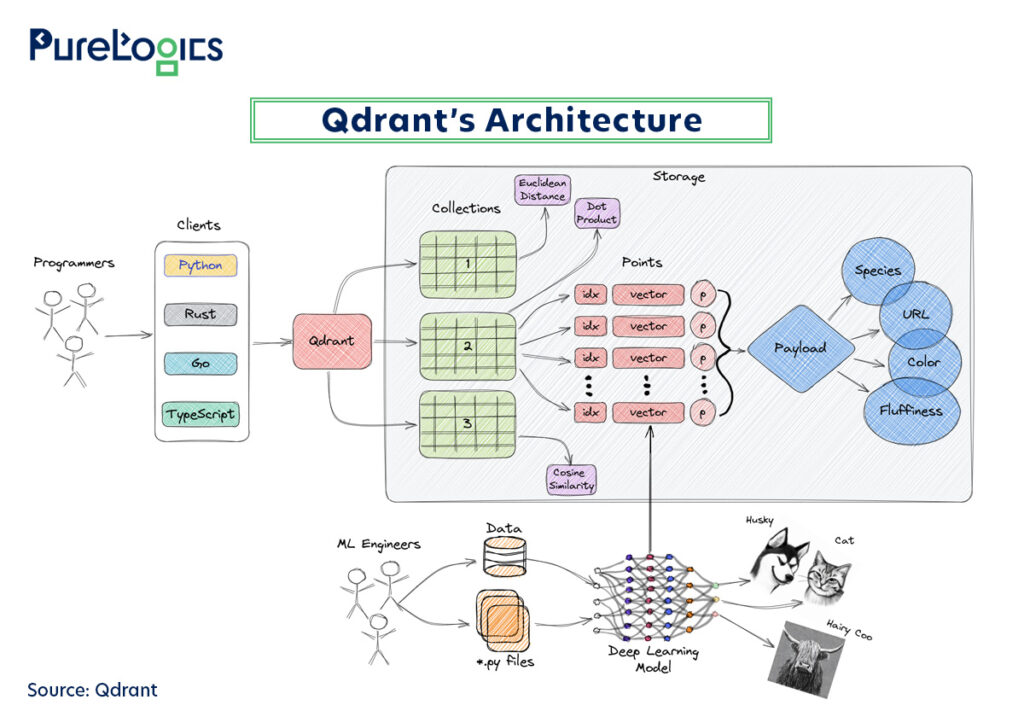
Qdrant is effective for lightweight semantic search systems, and here is how it works:
- Engineers and programmers create data and queries using deep learning models to convert data (like images of animals) into numerical vectors.
- Programmers then use client libraries (like Python, Rust, or Go) to send that data to Qdrant. It stores the vectors and their context, and the database organizes the vectors into “Collections.”
- Each vector is a “point” that includes a unique ID, the vector itself, and a “Payload,” which is extra information about the data.
- When a user searches, the Qdrant finds similar data by searching for similar vectors and compares the query’s vector to all the stored vectors. It uses different distance metrics (like Cosine Similarity or Euclidean Distance) to find the most similar ones and returns the corresponding data from the payload.
Let us tell you about its pros and cons:
| Pros | Cons |
| Supports users to run it on their own infrastructure without managed services constraints | Limited scalability and feature set |
| Efficient and known for its simplicity | Small and less vibrant community |
| Offers both vector search and filtering with traditional data fields | Fewer third-party tools and developer support than Weaviate or Milvus |
| Optimized for performance with good indexing speeds and minimal latency | |
| Great choice for small to medium-sized vector search applications |
The code below shows how to convert plain text into embeddings, and then store and search them in Qdrant. By running it, you can build a mini semantic search engine where “car” finds “automobile” instead of failing like a keyword search would.
from qdrant_client import QdrantClient
from qdrant_client.http.models import VectorParams
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
documents = ["car", "automobile", "dog"]
client = QdrantClient(url="http://localhost:6333")
client.recreate_collection(
collection_name="example_collection",
vectors_config=VectorParams(size=384, distance="Cosine")
)
for i, doc in enumerate(documents):
client.upsert(
collection_name="example_collection",
points=[{
"id": i,
"vector": model.encode(doc).tolist(),
"payload": {"text": doc}
}]
)
results = client.search(
collection_name="example_collection",
query_vector=model.encode("car").tolist(),
limit=2
)
print(results)Qdrant offers users the option to start with a 1GB managed cluster at no cost, with no credit card required. Additionally, users can connect their infrastructure from any cloud provider at $0.014 per hour. For private cloud hosting, Qdrant provides customized pricing.
Indeed, all these vector databases mentioned above have their strengths and weaknesses, and choosing between them can be difficult. If you are confused, then read the tips below to select what’s best for your project.
Confused? Read Proven Tips to Choose the Best Vector Database
If you are unable to choose the vector database, then let us provide you with four proven tips that can help select the best one according to your needs.
- Ease of use: Select a vector database that has a user-friendly interface and comprehensive documentation. Additionally, it should be easy to set up, insert data, and perform queries.
- Performance: The vector database should offer fast query performance even for large volumes of high-dimensional data.
- Scalability: Ensure the vector database is flexible and scales with your data growth, handling both current and future data volumes.
- Community support: Choose a vector database that hosts a strong and vibrant community for faster assistance and access to shared resources.
If you are still unsure about which vector database to choose, don’t worry; most offer free trials and demos, so you can try a few and see what fits your needs. Or book a free 30-minute call with our experts to get clear, practical guidance.
Now you know all about vector databases and how to choose the right one for your upcoming project. However, the technology world is changing rapidly, particularly with the widespread adoption of AI across various industries.
Future of Vector Databases
The future of vector databases appears promising as AI adoption accelerates across various industries. With the growing reliance on machine learning, the demand for efficient vector-based storage and retrieval will continue to increase. Key trends include:
- Smarter embeddings: Advanced AI models will enhance embeddings, resulting in more accurate and relevant search results.
- Wider industry use: Healthcare, legal, and finance will adopt it for image analysis, document retrieval, and fraud detection.
- Easier adoption: Managed services and cloud solutions will simplify usage, lowering barriers for companies without deep AI expertise.
- Hybrid Integration: Closer ties between SQL/NoSQL systems and vector databases for flawless data architectures.
Frequently Asked Questions
What are the examples of vector databases?
Vector databases are highly adaptable for both small and large-scale projects. However, for small projects, open-source tools like Chroma and Weaviate provide strong functionality. In contrast, at the enterprise level, platforms like Pinecone offer the best scalability.
Which vector database is best?
It depends upon the needs of your project.
- For smaller projects, a cost-effective and easy-to-use solution like Chroma and Weaviate provides strong functionality.
- For enterprise-scale projects, vector databases that support advanced features such as scalability, high availability, and optimized performance are best, such as Pinecone.
Does AWS have a vector database?
AWS not only offers a vector database but also provides multiple services with vector search capabilities. For instance, you can use Amazon OpenSearch Service with its k-NN plug-in to store and query embeddings, or Amazon Kendra for semantic document search. Additionally, Amazon Bedrock enables building generative AI applications that integrate embeddings and vector retrieval.
Why is vector db best for AI solution development?
Vector databases are designed for low-latency queries, making them best for AI app development. Additionally, their growing popularity is also due to the ability to provide the speed and efficiency required to power generative AI solutions.
